cleaning up text
see also being kind to the reader, editing, typing
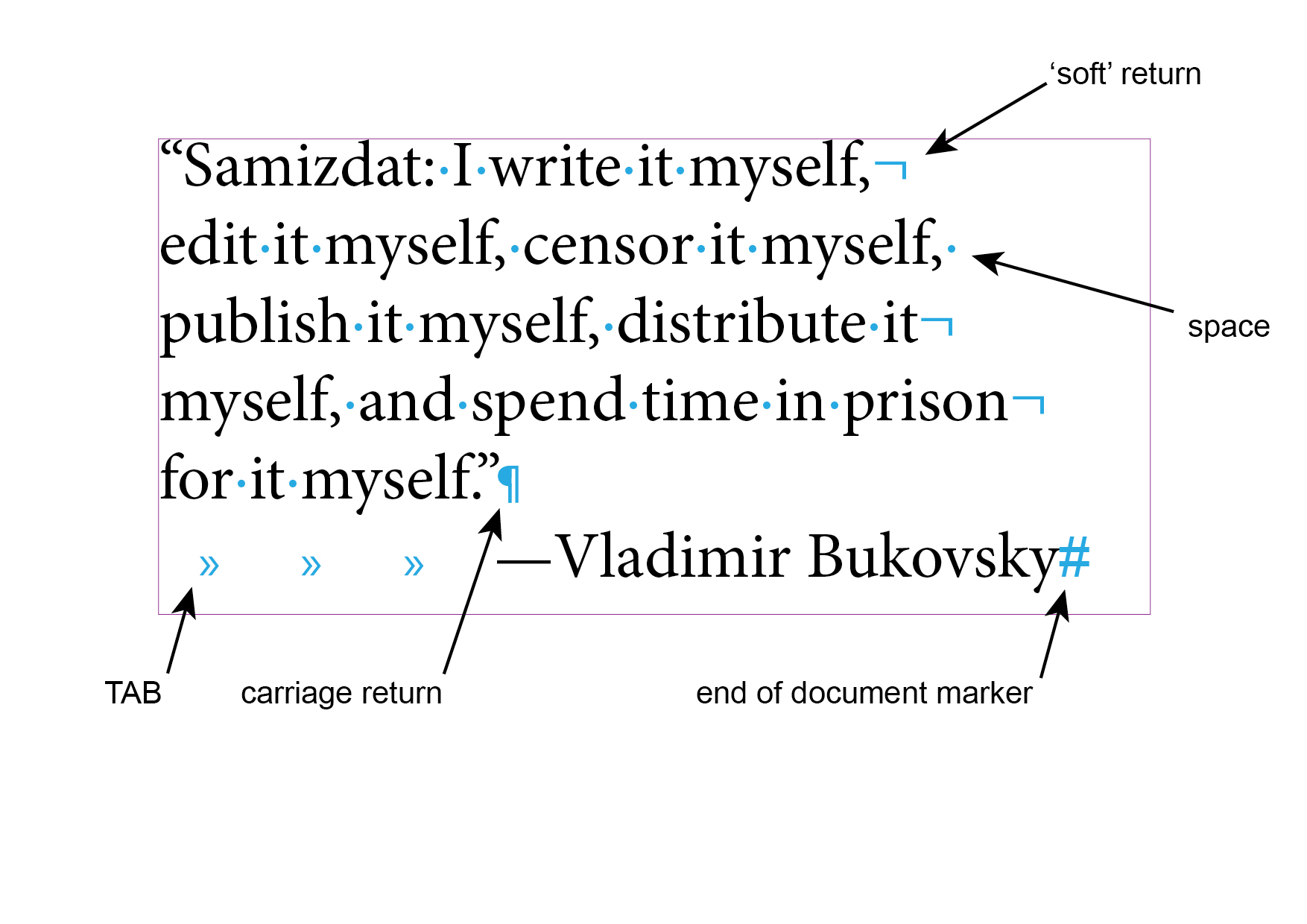
A text found in the wild often comes with visible and invisible artefacts. The visible ones come from bad OCR, with strange characters popping up in place of the ones you expect, such as a 1 instead of an l. The bane of the bootlegger is most definitely the line break or “soft return”, inserted by software that automatically breaks the line as you type. Screen-based formats such as EPUB don’t have the notion of a page, and flow text according to window size.
You can either be methodical and remove each soft return manually, or use the powerful automated find/replace all option. A useful tactic is to find every instance of a full stop followed by a space where a line was intentionally broken by the human writer. Next, replace each full stop with an arbitrary but uncommon character, such as a dagger (†). Then, do another find/replace and remove every instance of a soft return and a space, and finally replace the uncommon character with a full stop, in one final find/change command. Another unwanted character that often appears is the hyphen, inserted where words break at the end of a line. Here the pruning of errant characters is trickier, and the best method is to find and remove each instance manually. Running find/replace all can often remove necessary hyphens, such as in time ranges (e.g. 9-5) and compound adjectives (e.g. inter-dependent).
Image: Hidden characters (e.g. tabs, spaces, carriage returns and “soft” returns)